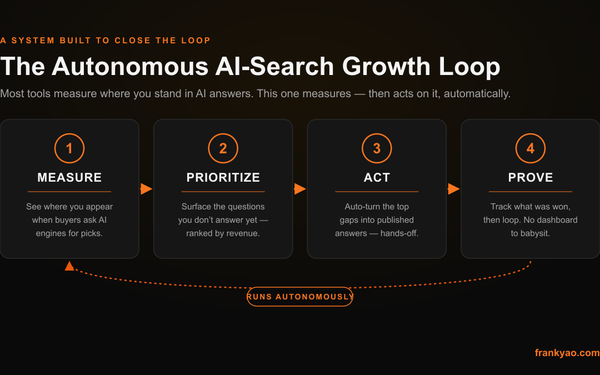
AI 智能体系统为什么会失败,以及如何修复它们
大多数 AI Agent 系统不会突然崩溃,而是在仪表盘一片绿色时悄悄腐烂。Agentic 系统失效的 6 种方式,以及真正站得住的修复方法。
Quick Check
对还是错:AI 工具将在 2 年内完全取代 SEO 的需求。
AI 智能体系统很少会伴随着错误消息死掉。
它会安静地死掉。与此同时,仪表盘仍然一片绿色。
我最近拆解过一个这样的系统,一个“基本能用”的系统。它底层实际是这样的:一整面墙的红色告警,其中一半是假的。一个从来没真正上过班的清理队。一个只安装在一台服务器上的修复,在另一台服务器上又被悄悄撤销。还有一个所有人都叫“坏了”的功能,最后发现其实是四个小故障套着一件大风衣。
这件事完全不是模型笨。全都是管道问题。
如果你正在生产环境里跑智能体,或者正准备这么做,下面是它们腐烂的六种方式,以及能阻止这些问题的那些无聊修复。
太长不读
- AI 智能体系统通常失败在*基础设施*层,而不是推理层。换一个更聪明的模型解决不了这些问题。
- 最危险的故障不是崩溃,而是假绿仪表盘(或者一个假红仪表盘,把你训练成忽略告警的人)。
- 把正确性内建到那个*创建*工作的东西里,而不是寄希望于下游某个“清理”任务会运行。
- “完成”意味着代码运行的*所有地方*都完成了,并且是对真实线上系统验证过,而不是对某个存储状态验证过。
- 每个自动化循环都需要五样东西:负责人、预防、检测、闭环和复盘。少一个,你就是安排了一次静默失败。
智能体系统里真正会坏掉的是什么?
让人不舒服的地方在这里。当人们想象自己的 AI 智能体失败时,他们脑子里通常是模型失控、幻觉、死循环、输出废话。这些确实会发生,而且很显眼,你能抓到。
真正造成伤害的是那些看不见的失败。它们存在于智能体之间的线路里:工作如何被创建,如何被检查,你如何知道某件事停了。智能体系统本质上是一个碰巧会思考的分布式系统。而分布式系统不会大声失败。它们会漂移。
下面是六种具体的漂移模式,每一种都来自真实系统,每一种都已经脱敏,只保留教训。如果你在运营智能体,你现在大概率至少有三种正在运行,只是你还不知道。
为什么 AI 智能体会创建同一个任务 93 次?
把这个叫作从未出现的清洁工。
系统每次发现问题时都会创建一个任务。合理。问题是它从来不检查完全相同的任务是否已经存在。所以七个真实问题被写了九十三次。工作队列看起来像灾难现场。实际上只是七件事站在一间镜子大厅里。
“解决方案”也早就存在了,一个设计用来合并重复项的清理任务。只是它从来没被打开过。正确性被外包给了一个从来没打卡上班的清洁工。
这是智能体系统里最常见的腐烂模式,因为智能体是*生成器*,它们会生成工作、消息、记录、调用。而一个没有记忆的生成器会重复自己。无休止地。安静地。直到队列 90% 都是噪音,真正的信号被淹没。
修复方法:把去重内建到那个*创建*工作的东西里,而不是那个本该事后清理的东西里。写入任务的原语应该在源头、每次调用时,通过检查是否已有同 key 的未关闭任务,来拒绝写入重复项。一个你“希望会运行”的下游清理器不是安全网。它只是愿望。让操作具备幂等性,重复问题就会停止存在,而不是等以后再被扫掉。
原则:永远不要把正确性外包给清洁工。把它烤进原语里。 我在我的 AI 协作 4D 框架里写过更多关于如何构建可重复系统,而不是一次性修复的内容,同样的逻辑也适用于这里。创建工作的系统,是唯一能免费阻止重复项的地方。
你的监控在骗你吗?
这是最吓人的一个。
仪表盘上大约一半的红色都是假的。健康检查把每周任务标成“已死亡”,因为它们是按每日节奏衡量的。一个审计任务尖叫着说链接坏了,但那些链接一周前就修好了。另一个标记了已经不存在的页面。一个“渲染”检查在一个它根本不适用的框架构建的网站上大声失败。
而且监控还在重新读取旧快照,而不是重新检查真实线上系统,所以它持续重新抛出那些早已解决的问题。
这之所以危险,不只是烦人:误报不是无害噪音。它会*训练操作员忽略仪表盘。* 这是可靠性工程里最老的教训之一,Google 自己的 SRE 手册专门有一章讲它,因为告警疲劳就是真实故障溜过去的方式(见 Google 的《监控分布式系统》章节)。每一次错误告警都会多花掉一点团队的信任。等真正起火的那天,它会和其他静电噪音一起死在背景里。
镜像问题更糟:一个假绿的仪表盘,在核心功能已经死亡时仍然报告健康,这种问题通常会以客户告诉你产品坏了而收场。
修复方法:把审计当成*线索,而不是判决。* 在任何人对红旗采取行动前,先针对真实线上系统重新运行检查。这个 URL 真的返回错误吗?这个页面真的渲染为空吗?这个任务真的是每天运行,还是一个每周任务被错误地按每日时钟评判?一个经过验证的“这个告警是假的”,然后*修好告警让它停止喊狼来了*,是真工作,不是捷径。
原则:假红和假绿一样昂贵。一个浪费你的时间;另一个隐藏你的火情。动手改任何东西前,先对现实做验证。
那些从来不重要的告警该怎么办?
埋在那面红墙里的,还有几个测试任务,是几个月前有人为了检查某件事临时启动的,然后忘了。它们还在报警。永远报警。纯噪音披着信号的外衣。
智能体系统会像车库堆箱子一样积累这些东西。一次调试会话留下的探针。一个已经上线并继续前进的功能的金丝雀。一个已经悄悄退役的任务的心跳。它们都不再意味着任何东西,但全都还在点亮仪表盘。
修复方法:死掉的东西一死就退休。每一个不要求行动的告警,都会稀释每一个真正要求行动的告警。把你的监控面板想象成预算,你只有这么多人的注意力,超过后人们就不再看了,所以只把它花在你真的会采取行动的信号上。
为什么一个“坏掉”的功能会有四个原因?
有一个能力就是……不工作。所有人都叫它坏了,然后继续做别的事。就是那种会在 backlog 里挂着“以后调查”一个月的东西。
它不是一个故障。它是四个故障堆在一起,而且每一个单独看都很合理:
- 代码已经写了,但从来没有推到线上,
- 它的输出卡在一个没人清理的审批步骤后面,
- 一个步骤悄悄缺失了(输出里从来没有附上图片),并且
- 本该标记这一切的告警几周前被静音了。
这些问题单独任何一个都是五分钟修复。放在一起,它们看起来像一个谜。而谜题会被降级优先级,因为没人能估算它。
这就是让智能体系统感觉“抽风”的原因。一个抽风的系统几乎从来不是一个抽风的东西。它是一条链条:创建、发布、触发、生成、交付、验证,在三个不同环节各有一个看起来很合理的小缺口。每个缺口都通过了自己的局部审查。整条链条仍然承载不了。
修复方法:当某件事“不工作”时,不要去找*那个* bug。沿着*整条链*从头到尾走一遍,并验证每一跳都传递成功。故障几乎总是一堆小缺口,而不是一个戏剧性的大故障。
原则:“它坏了”很少只是一件事。它是一叠东西。先追踪整条路径,再做理论推断。 选择正确工具在这里也很重要,我在真正重要的 AI 工具里深入写过,但没有任何工具能拯救一条你从未追踪过的链。
为什么同一个 bug 在你修好后又回来了?
这个系统运行在两个环境里。一个修复进了其中一个环境,验证通过,正常工作,大家庆祝,然后它在另一个环境里完全不存在,而一半任务实际上是在那里跑的。“已修复”同时为真也为假,取决于你问哪台机器。
这种腐烂模式会让工程师觉得自己快疯了。你修好了。你看着它工作。一周后它又回来了,而你写的 diff 仍然好端端地在那里。修复是真的。它只是从未到达代码存在的第二个地方。
智能体系统很快就会横跨多个表面:一台笔记本、一台服务器、一个 serverless function、三个不同运行时,因为它们就是这样生长的。一个只落在一个表面而没有落在其他表面的补丁,不是修复。它是一个自带过期时间的修复。
修复方法:“完成”意味着*代码运行的所有地方*都完成。在关闭一个修复前,列出受影响代码会执行的每一个环境,并确认变更已经在每一个环境上线。如果你列不出来,那才是真正的 bug,你已经失去了对自己表面积的掌控。
你应该相信系统对自己的说法吗?
最诱人的失败:相信系统上周对自己*报告*的状态,而不是检查现在真实发生的事情。
存储摘要会漂移。快照会过期。一个写着“已上线”的缓存状态,随着时间推移,会变成一个公关做得不错的传闻。智能体尤其容易出现这种问题,因为它们依赖上下文运行,而上下文只是带着自信语气的存储状态。一个智能体会告诉你某个任务完成了,因为一条笔记说它完成了,而不是因为它真的看过。
修复方法:在任何长期运行的智能体系统里,默认把存储状态视为可疑。在你声称某件事已完成、已上线或已死亡之前,去看真实来源。数据库行。线上 URL。实际 API 响应。不是那条说一切都好的笔记。不是三次会话前的摘要。
原则:昨天的状态就是传闻。每一次都要用真实系统验证“完成”。 对会总结自己工作的 AI 智能体来说,这一点尤其正确,摘要是假设,真实系统才是唯一裁判。
一个“闭环”到底需要什么?
注意这份清单里*没有*什么。这六个失败里,没有一个是推理失败。没有人需要更聪明的模型、更大的上下文窗口,或者更巧妙的提示词。每一个都是基础设施问题:幂等性、诚实监控、死亡信号卫生、全链路追踪、完整发布,以及对现实而不是记忆做验证。
这才是运行智能体的真正教训。智能现在是容易的部分,你可以按 token 租用。真正决定你的智能体是安静腐烂还是安静复利的,是那种不迷人的闭环纪律。
一个循环只有具备以下五样东西,才算闭合:
负责人,当它失败时,有一个具名的人或智能体负责。不是“它在服务器上运行”。要有名字。
预防,坏情况在源头被设计掉:幂等性、上限、超时、合理默认值。
检测,一个*正向*心跳,让沉默本身成为告警。“运行了但什么都没发现”绝不能看起来和“没能运行”一模一样。它们是相反状态,你的监控必须能区分它们。
闭环,一旦失败,它会自动修复,或者升级成一个有跟踪、有负责人、有截止日期的任务。永远不要是一个发出去就忘、从屏幕上滚走的告警。
改进,有人按计划复盘它并调优它。
少了其中任何一个,你拥有的就不是一个自动化任务。你拥有的是一个还没爆发的定时静默失败。
这就是全部游戏。构建循环。对现实验证。让僵尸退休。追踪完整链路。发布到所有地方。不信任摘要。做到这些,你的智能体就会停止腐烂,开始复利,而这正是你构建它们的全部原因。
常见问题
为什么 AI 智能体系统更常失败在基础设施层,而不是模型层? 因为模型是你租来的、会测试的、会观察的部分,所以它的失败可见,你能抓到。智能体之间的线路(工作如何被创建、检查和监控)是定制的、不可见的,并且很少在失败条件下测试。漂移就是在那里安静积累的。更强的模型对一个会生成重复任务的队列,或者一个撒谎的仪表盘,没有任何帮助。
智能体系统里最危险的单一故障模式是什么? 是一个错误报告现实的仪表盘,无论方向是哪一种。假绿面板会把一个死亡功能藏起来,直到客户发现。假红面板会训练你的团队忽略告警,于是唯一真实的告警也会被当成噪音一起丢掉。诚实监控是其他一切的地基。
我该如何阻止智能体创建重复工作? 让创建工作的操作具备幂等性。在它写入任务、消息或记录之前,应该检查是否已经存在一个同 key 的未关闭项,并更新它,而不是插入一个新的。把这件事内建到创建工作的原语里,不要依赖单独的清理任务,因为后者只有在有人记得安排和维护它时才会运行。
为什么我已经发布的修复会不断回来? 几乎总是因为你的代码运行在不止一个环境里,而修复只到达了其中一个。在关闭任何修复前,列出受影响代码执行的每一个地方,每台服务器、每个运行时、每个函数,并验证变更已经在每一个地方上线。如果你拿不出这份清单,丢失的表面积才是真正的 bug。
一个定时智能体任务被认为安全所需的最低条件是什么? 五样东西:一个具名负责人,一个针对明显失败的内建预防机制,一个正向心跳,让沉默成为告警,一个失败时的自动闭环或升级路径,以及一次周期性复盘。任何少了其中之一的东西,都是一次等待发生的静默失败,只是它还没发生而已。
如果我的智能体系统已经感觉很不稳定,我应该从哪里开始? 从仪表盘开始,而不是从智能体开始。在你触碰任何一个提示词之前,先审计你的监控:随机挑三个告警,然后现在就针对真实线上系统重新运行每一个。数一下其中有多少已经是假的。这个数字会告诉你,你所谓的“坏掉”有多少是真的。然后挑一个所有人都说坏了的功能,从头到尾走一遍:创建、发布、触发、生成、交付、验证,并检查每一跳是否真的承载成功。你几乎总会发现,腐烂在管道里,而不是推理里,而且两个无聊修复(幂等任务创建和诚实心跳)会移除大部分噪音。先修信号;你无法调试一个你已经学会忽略其告警的系统。
---
*正在构建这类系统?我运营着一个社区,里面会交流这些真实复盘和真正站得住的修复方案,来一起对照笔记。如果你想了解这一切背后的操作哲学,可以从我是如何真正与 AI 协作的开始。*
Where Are You Right Now?
你的业务目前在 AI 方面最大的挑战是什么?